
For the last couple of months I haven’t written a single line of code by hand. Not because I stopped working (quite the opposite), but because I’ve moved almost entirely to working with AI agents instead of typing the code myself. In that time I’ve shipped complex features to production with zero incidents and zero rollbacks, and honestly with more confidence than before, because the agent’s eyes reach places mine would never think of checking in the first place.
I gave an internal talk about this to some teammates, and a few of them asked me to write it down so they could share it around. So here it is. This is how I work, not a standard or a mandate. Take what’s useful and leave the rest.
The cool things about my workflow is not that “the AI writes the code” and magic happens. The interesting part is the setup around it, the thing that keeps me in control while the agent does the typing. There are four pieces to it:
CLAUDE.mdfiles to teach the model what the code can’t tell it.- Superpowers, an agentic framework that brings structure and discipline to building with agents.
- My own curated skills that encode how I (and my team) like to work.
- MCPs that plug the agent into real systems for live data and actions.
I mostly use Claude Code, so that’s what I’ll reference throughout, but most of this applies to any model and harness. Let’s go through each piece, and then I’ll show you the whole thing running on real work.
1. Teach the model with CLAUDE.md
A CLAUDE.md file at the root of your repository is auto-loaded as context on every session. Think of it as the project’s memory: the place where you write down everything the model couldn’t figure out just by reading the code.
That last sentence is the whole rule for what goes in. Concretely, I put in:
- Business rules and domain vocabulary. This is the big one. If I teach the model what a “guest user” is, or what is the difference between a team admin and a organization admin in our system, I can then talk to it naturally and it already knows what I mean, so I don’t have to re-explain it every session.
- Why a module exists, the architectural intent behind a piece of code. The why, not the what.
- Gotchas and footguns, in the shape of “don’t do X because Y, do Z instead”.
- Conventions that aren’t enforced by linters, the unwritten rules every team has.
And I leave out anything that’s obvious from the code, anything auto-generated, and full API docs. The file is loaded into every conversation, so keeping it short and high-signal matters. If it’s bloated with stuff the model doesn’t need, you’re just distracting it (and burning context) on every task. I try to keep mine under ~200 lines.
CLAUDE.md and not AGENTS.md? Claude Code doesn’t read AGENTS.md by default, while editors like Cursor read both. So CLAUDE.md ends up being the one file to rule them all, the same context shared across the tools I use.Close the file with a set of rules
After the domain knowledge, I close every CLAUDE.md with a block of explicit rules the agent must follow. If the domain section is the “what you need to know about this project”, the rules are the “how I want you to behave” layer on top, and they’re reusable across projects.
# CLAUDE.md
## Domain context
... (business knowledge, architecture intent, gotchas) ...
## Rules
These rules apply to every task unless explicitly overridden.
Bias: caution over speed on non-trivial work.
### Rule 1 — Think before coding
### Rule 2 — Simplicity first
...Writing these down turns implicit preferences into explicit instructions, which means a lot less back-and-forth correcting the agent over and over. These are the eleven I ship in basically every project (you can check all of them in detail in GitHub):
- Think before coding. State assumptions. Ask, don’t guess.
- Simplicity first. Minimum code, nothing speculative.
- Surgical changes. Touch only what you must.
- Goal-driven execution. Define success, then loop until it’s verified.
- Use the model for judgment only. If code can answer the question, code answers it.
- Surface conflicts. Pick one pattern, don’t blend two.
- Read before you write. Exports, callers, shared utilities.
- Tests verify intent. Encode why the behaviour matters, not just what it does.
- Checkpoint each step. Summarize what’s done, verified, and left.
- Match conventions. Conformance over taste inside a codebase.
- Fail loud. “Done” is wrong if anything was silently skipped.
A couple of these earn their keep more than the rest. I love rule 5, because it nudges the model to write a small throwaway script or test to validate a hypothesis instead of guessing from its reading of the code. Rule 8 matters because models love to write useless tests that only check the thing runs without throwing, instead of actually pinning down the behaviour. And rules 2 and 3 are what keep the agent from quietly expanding the scope of a task. I sometimes point back to a specific rule mid-task when I want the model to pay more attention to something.
2. A repeatable workflow with Superpowers
Superpowers is an agentic framework packaged as a Claude Code plugin, but can be used with any harness as it’s available in GitHub. Under the hood it’s a library of interconnected skills (focused instructions the agent invokes automatically when they’re relevant), but what it really gives you is a repeatable workflow that bakes in solid, battle-tested engineering practices that also happen to work great with LLMs, like TDD and divider-and-conquer strategies.
If you’re wondering whether this is just another trendy tool, it’s worth noting it sits at over 239,000 stars on GitHub as I write this. That’s more than the Linux kernel itself. It has become something of a de facto standard.
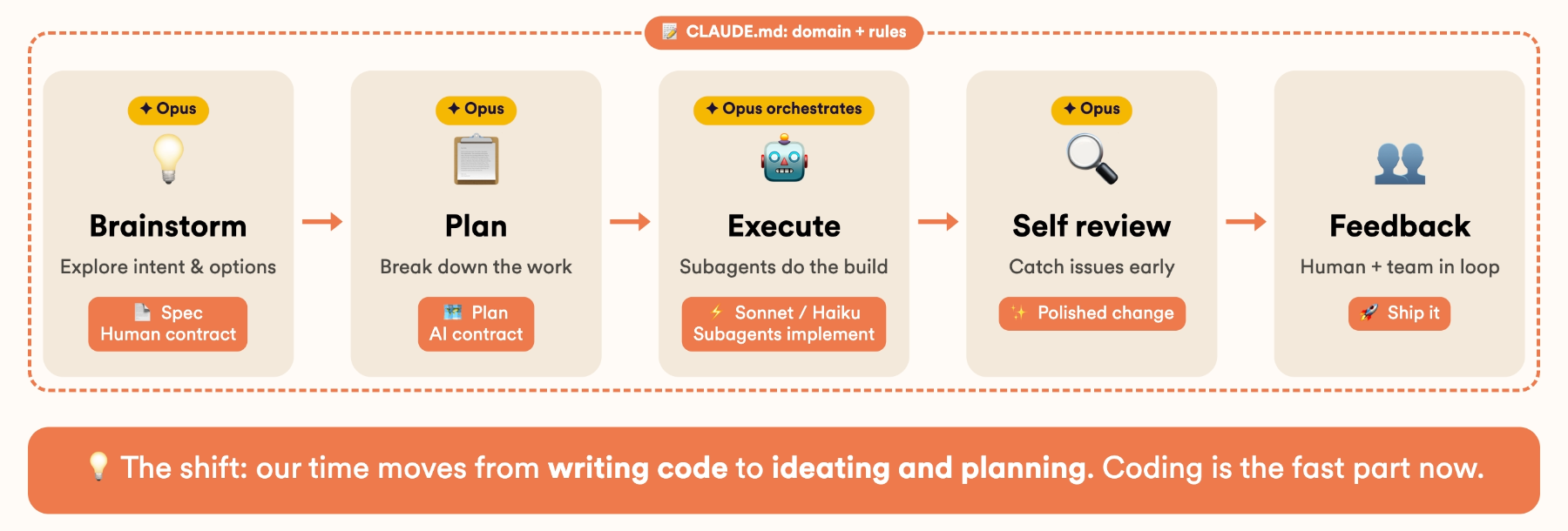
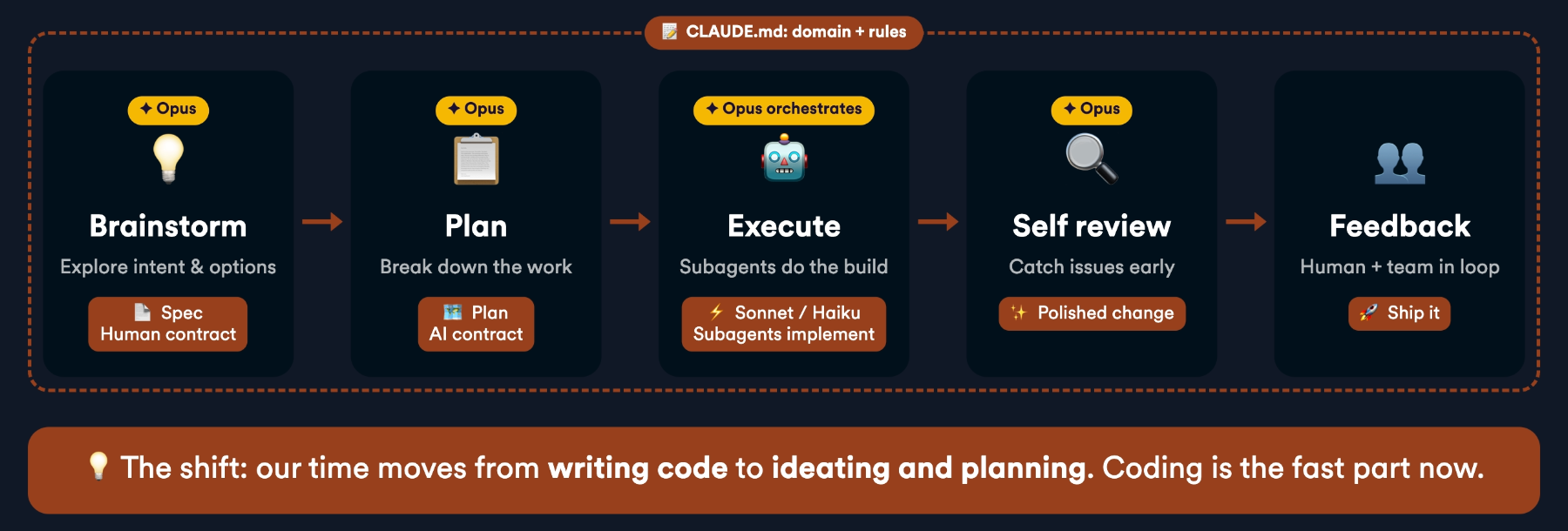
The reason this works isn’t the code generation itself, it’s that the structure produces the right artifacts at the right time and keeps you in control. Here’s the core loop I run:
Click on image to enlarge
- Brainstorm. The agent reads the relevant code, explores the intent with me, and proposes a few options. The output is a spec.
- Plan. The spec becomes a detailed, step-by-step plan with TDD enforced. The output is a plan file.
- Execute. Subagents build it, one task at a time, parallelizing when the work allows.
- Self-review. The change is reviewed before I even look at it, catching issues early.
- Feedback. Human and team feedback gets folded back in (Superpowers has skills for that part too).
A nice detail on cost and quality: I run the brainstorming, planning, orchestration and review on the most capable model (Opus), while the implementer subagents doing the actual typing run on cheaper, faster models (Sonnet or Haiku). The expensive thinking happens up front, where it’s worth it.
And that’s the real shift here. Agentic development moves my time from writing code to ideating and planning. Coding is the fast part now.
Two contracts that keep you in control
The two artifacts above aren’t bureaucracy, they’re contracts, and understanding the difference between them is what makes this whole thing click.
- The spec is the human contract. It’s the output of brainstorming: the what, the why, and the high-level how, written for me to read. It’s short, and I must accept and approve it before before any planning happens.
- The plan is the AI contract. It’s the output of planning: the detailed how, concrete ordered steps, derived from the spec and, and the agent self-reviews it (the plan) against the spec. It’s machine-followable, it enforces TDD, and it can run to a thousand lines for complex work.
This is the important part to remark: the spec is the only human gate. I review and approve it, then the plan derives from it and self-reviewed. And then I let it build, and I only review the final code the same way I’d review a teammate’s pull request, not the plan. If the spec is right, the plan will be right.
I’ll be honest, I didn’t trust the plan at first and I read every one of them carefully. Over time I’ve learned that if I got the spec right, the plan follows. That single checkpoint is what lets me stay in control without babysitting every step.
The other skills it ships
The core loop isn’t everything Superpowers brings. It ships a whole catalog of skills the agent reaches for on its own, and a few examples give you the idea:
systematic-debuggingkeeps the agent honest when chasing a bug: it forms competing hypotheses and proves the root cause before proposing any fix, instead of patching the first plausible thing it finds.requesting-code-reviewspins up a fresh agent to review a finished piece of work against the spec, catching issues before I do.receiving-code-reviewtakes that feedback (or a teammate’s) and works through it point by point, pushing back or challenging when needed, instead of blindly applying every suggestion.
There are many more, and you rarely invoke them by hand since the agent picks the right one for the task. If you want the full picture, just browse the Superpowers repository on GitHub.
3. My own curated skills
Superpowers gives you a great generic workflow. But every team has its own standards, stack, and conventions, and that’s where your own skills come in. My team and I keep a small library of skills in a shared repository that encode exactly how we like things done, so the agent produces work that already looks like ours.
The ones I reach for most:
code-review, a review tuned to my team’s standards. It can replace the generic Superpowers self-review with one that knows what we actually care about: golden paths, established patterns, security audits, etc.prepare-pr, which organizes the commits and prepares the pull request once the self-review is done (code checks, PR description, labels, issues, references, etc.). It saves a lot of busywork at the end of a task.- A
githubskill, tuned to how we use GitHub: opening PRs, reading issues, pulling review feedback, with our tags and templates baked in. - A
grafana-observabilityskill that knows how to query our production logs and metrics, so I can debug an ongoing issue right next to the code.
The pattern is always the same: I start with a Superpowers skill for the generic workflow, then hand off to my own skills to encode the team’s standards. For feature work that looks like brainstorm → plan → execute, then code-review, then prepare-pr and github to open the PR. For a bug, I start with systematic-debugging, pull in the grafana-observability skill to inject real production data, then the same code-review and PR skills at the end.
4. MCPs: live access to our systems
The last piece are the Model Context Protocol (MCP) clients/servers. If skills are the know-how, MCPs are the hands and eyes: they let the agent read from and act on external systems through a standard interface. Configure once, use everywhere. The ones I lean on:
- Slack. Paste a thread URL and the agent pulls the whole discussion, often the reasoning behind a change that never made it into a commit message or a GitHub issue.
- GitHub. Open PRs, read issues, pull the team’s review feedback.
- Grafana / Loki. Read production logs and debug with the logs and the code side by side.
- Backstage. A service catalog. The source of truth for services, docs, ownership, and how things relate.
The mental model to internalize is that skills and MCPs are different things that combine. A skill is the procedure (how to investigate a production issue well). An MCP is the access (the actual logs and metrics). As an example of how they combine:


Click on image to enlarge
Putting it all together, some examples
So that’s the setup: CLAUDE.md for context, Superpowers for the process, my own skills for the standards, and MCPs for live data. Stacking those four pieces is what produces the outcome I opened with. Higher-quality changes, shipped faster, on my (and my team’s) standards, with the AI reaching deeper than I would on my own.
Enough theory, let me show you it running on real work.
Example 1: from issue to pull request
It genuinely starts with a single prompt:
/brainstorming let's implement this issue:
https://github.com/my-org/my-repo/issues/1234And then I let the loop run in Claude Code’s auto mode:
- Brainstorm. The GitHub MCP reads the issue, and we agree on a spec.
- Plan. The spec becomes a step-by-step plan with TDD enforced.
- Execute. Subagents build it one task at a time, parallelizing when they can.
- Self-review. My
code-reviewskill checks it against the team’s standards. - Me-review. I review the code as I would do for another teammate’s PR.
- Feedback. I let the agent know of my feedback and it works on it using the superpowers’
receiving-code-reviewskill. - Share. The
prepare-prandgithubskills, plus the GitHub MCP, open the PR. - Feedback. Teammates’ review comments come back in through the MCP and feed straight into the
receiving-code-reviewskill.
That one prompt pulls together everything from this article. While the agent is working through the plan (usually 30 to 40 minutes), I have free time I normally spend reviewing other people’s PRs. Sometimes I even open a second tab and start brainstorming a related issue in parallel.
Example 2: debugging with production logs
Debugging starts the same way, one prompt with the symptom and links to the context:
/systematic-debugging why didn't sent the confirmation email to this user (<user_id>)?
There's more context in this Slack thread: <link>
It might be related to this PR: <link>And it runs the investigation end to end:
- Gather context. It reads the Slack thread (via the Slack MCP) and the linked PR (via the GitHub MCP).
- Trace the code. It follows the data flow and the git history, and forms competing hypotheses.
- Pull real data. Using the
grafana-observabilityskill (auto-invoked), it queries the production logs and metrics through the Grafana MCP (also covering Loki). - Cross-check. When the logs weren’t enough, it pivoted to querying the database directly for ground truth (we also have a skill for agents to check a read-replica of the database with PII anonymized).
- Stays honest. It proposed no fix until the root cause was proven, dropping its own wrong hypotheses by validating the actual code behaviour (this is rule 5 from my
CLAUDE.mddoing its job). - Root cause. It landed on a data edge case that fell between two business rules. Not a code bug at all, which is exactly the kind of conclusion I’d have spent hours arriving at by hand.
That was a real, 20-plus-minute autonomous investigation. The systematic-debugging discipline is what kept it from jumping to a plausible-but-wrong fix, and the MCPs are what gave it real data to reason about instead of guesses.
Wrapping up
None of this removes the engineer from the loop. If anything, it puts me more firmly in the part that actually matters: deciding what to build and why, and reviewing the result with a critical eye. The agent handles the typing, but the spec is mine, the standards are mine, and the final review is mine.
If you want to start somewhere, start with CLAUDE.md. Write down the things about your project the code can’t say out loud, add a handful of rules at the end, and see how much less you have to repeat yourself. Then add Superpowers for the workflow, grow your own skills as you notice yourself correcting the same things, and wire up the MCPs for the systems you live in.
This leans on the same thing every healthy engineering practice does: trust, and being explicit about how you work. It’s the same foundation I wrote about in the “Ship, Show, Ask” git strategy and in how to manage technical debt. Make your way of working explicit, and the agent can follow it.
That’s how I work today. Take what’s useful, leave the rest, and keep it going!